Schema Evolution
Schema evolutions are a feature you can use to update your whole Data Flow to reflect edits to a collection, preventing your Data Flow from failing due to mismatched components.
Evolutions are a relatively advanced concept in Estuary. Before continuing, you should have a basic understanding of Estuary's captures, collections, schemas, and materializations.
Introduction
Estuary stores your real-times datasets as collections, groups of continually updating JSON documents. Captures write data to collections, and materializations read data from collections. Together, these three components form a complete Data Flow.
Derivations can also read data from and write data to collections. To keep things simple in this article, we'll be referring only to captures and materializations.
Each collection and its data are defined by a collection specification, or spec. The spec serves as a formal contract between the capture and the materialization, ensuring that data is correctly shaped and moves through the Data Flow without error.
The spec includes the collection's key, its schema, and logical partitions of the collection, if any.
When any of these parts change, any capture or materialization writing to or reading from the collection must be updated to approve of the change, otherwise, the Data Flow will fail with an error.
You can use Estuary's schema evolutions feature to quickly and simultaneously update other parts of a Data Flow so you're able to re-start it without error when you introduce a collection change.
Collection specs may change for a variety of reasons, such as:
- The source system is a database, and someone ran an
ALTER TABLEstatement on a captured table, so you need to update the collection schema (through AutoDiscover or manually). - The source system contains unstructured data, and some data with a different shape was just captured so you need to update the collection schema (through AutoDiscover or manually).
- Someone manually changed the collection's logical partitions.
Regardless of why or how a spec change is introduced, the effect is the same. Estuary will never permit you to publish changes that break this contract between captures and materializations, so you'll need to update the contract.
Using evolutions
When you attempt to publish a breaking change to a collection in the Estuary web app, you get an error message that looks similar to this one:
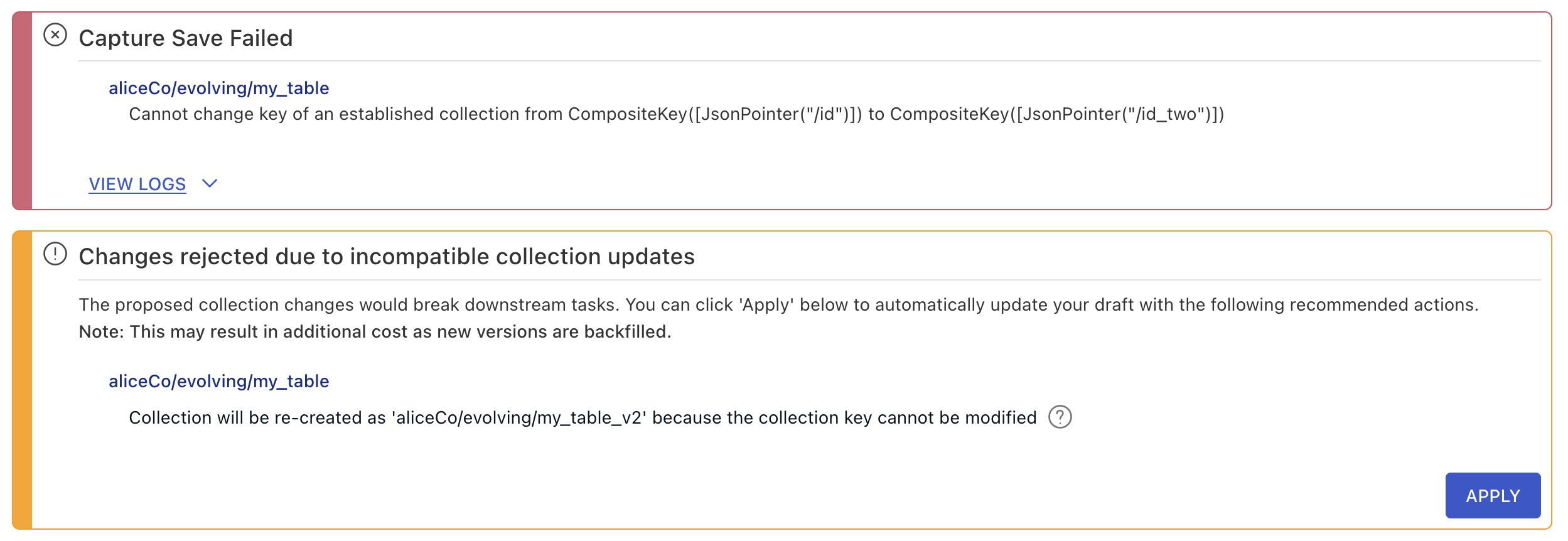
Click the Apply button to trigger an evolution and update all necessary specification to keep your Data Flow functioning. Then, review and publish your draft.
If you enabled AutoDiscover on a capture, any breaking changes that it introduces will trigger an automatic schema evolution, so long as you selected the Breaking change re-versions collections option (evolveIncompatibleCollections).
What do schema evolutions do?
The schema evolution feature is available in the Estuary web app when you're editing pre-existing entities. It notices when one of your edits would cause other components of the Data Flow to fail, alerts you, and gives you the option to automatically update the specs of these components to prevent failure.
In other words, evolutions happen in the draft state. Whenever you edit, you create a draft. Evolutions add to the draft so that when it is published and updates the active data flow, operations can continue seamlessly.
Alternatively, you could manually update all the specs to agree to your edit, but this becomes time-consuming and repetitive.
Evolutions can prevent errors resulting from mismatched specs in two ways:
-
Materialize data to a new resource in the endpoint system: The evolution updates the affected materialization bindings to increment their
backfillcounter, which causes the materialization to refresh the resource (database table, for example) and backfill it from the beginning. If the schema change requires a different table structure (such as an incompatible column type change or a primary key change), the resource is dropped and recreated; otherwise it is truncated, preserving table-level metadata such as partitioning and clustering.This is a simpler change, and how evolutions work in most cases.
-
Re-create the collection with a new name: The evolution creates a completely new collection with numerical suffix, such as
_v2. This collection starts out empty and backfills from the source. The evolution also updates all captures and materializations that reference the old collection to instead reference the new collection, and increments theirbackfillcounters.This is a more complicated change, and evolutions only work this way when necessary: when the collection key or logical partitioning changes.
In either case, the names of the destination resources will remain the same. For example, a materialization to Postgres refreshes the affected tables with the same names they had previously — typically by truncating, or by dropping and recreating when the schema change requires a different table structure.
Also in either case, only the specific bindings that had incompatible changes will be affected. Other bindings will remain untouched, and will not re-backfill.
The onIncompatibleSchemaChange field in materialization specs provides granular control over responses to incompatible schema changes.
This field can be set at the top level of a materialization spec or within each binding.
If not specified at the binding level, the top-level setting applies by default.
The onIncompatibleSchemaChange field offers four options:
- backfill (default if unspecified): Increments the backfill counter for affected bindings, refreshing the destination resources (truncating, or dropping and recreating when the schema change requires it) and backfilling them.
- disableBinding: Disables the affected bindings, requiring manual intervention to re-enable and resolve the incompatible fields.
- disableTask: Disables the entire materialization, necessitating human action to re-enable and address the incompatible fields.
- abort: Halts any automated action, leaving the resolution decision to a human.
These behaviors are triggered only when an automated action detects an incompatible schema change.
Manual changes via the UI will ignore onIncompatibleSchemaChange.
This feature can be configured using flowctl or the "Advanced specification editor".
What causes breaking schema changes?
Though changes to the collection key or logical partition can happen, the most common cause of a breaking change is a change to the collection schema.
Generally materializations, not captures, require updates following breaking schema changes. This is because the new collection specs are usually discovered from the source, so the capture is edited at the same time as the collection.
Consider a collection schema that looks like this:
schema:
type: object
properties:
id: { type: integer }
foo: { type: string, format: date-time }
required: [id]
key: [/id]
If you materialized that collection into a relational database table, the table would look something like my_table (id integer primary key, foo timestamptz).
Now, say you edit the collection spec to remove format: date-time from foo. You'd expect the materialized database table to then look like (id integer primary key, foo text). But since the column type of foo has changed, this will fail. An easy solution in this case would be to change the name of the table that the collection is materialized into. Evolutions do this by appending a suffix to the original table name. In this case, you'd end up with my_table_v2 (id integer primary key, foo text).